Processing datasets
The figure below illustrates a framework for processing tabular data in Pandas, showing the typical steps involved in transforming raw datasets into summarized and well-structured results. Each box represents a state of the DataFrame, and the arrows indicate how operations transform the data.
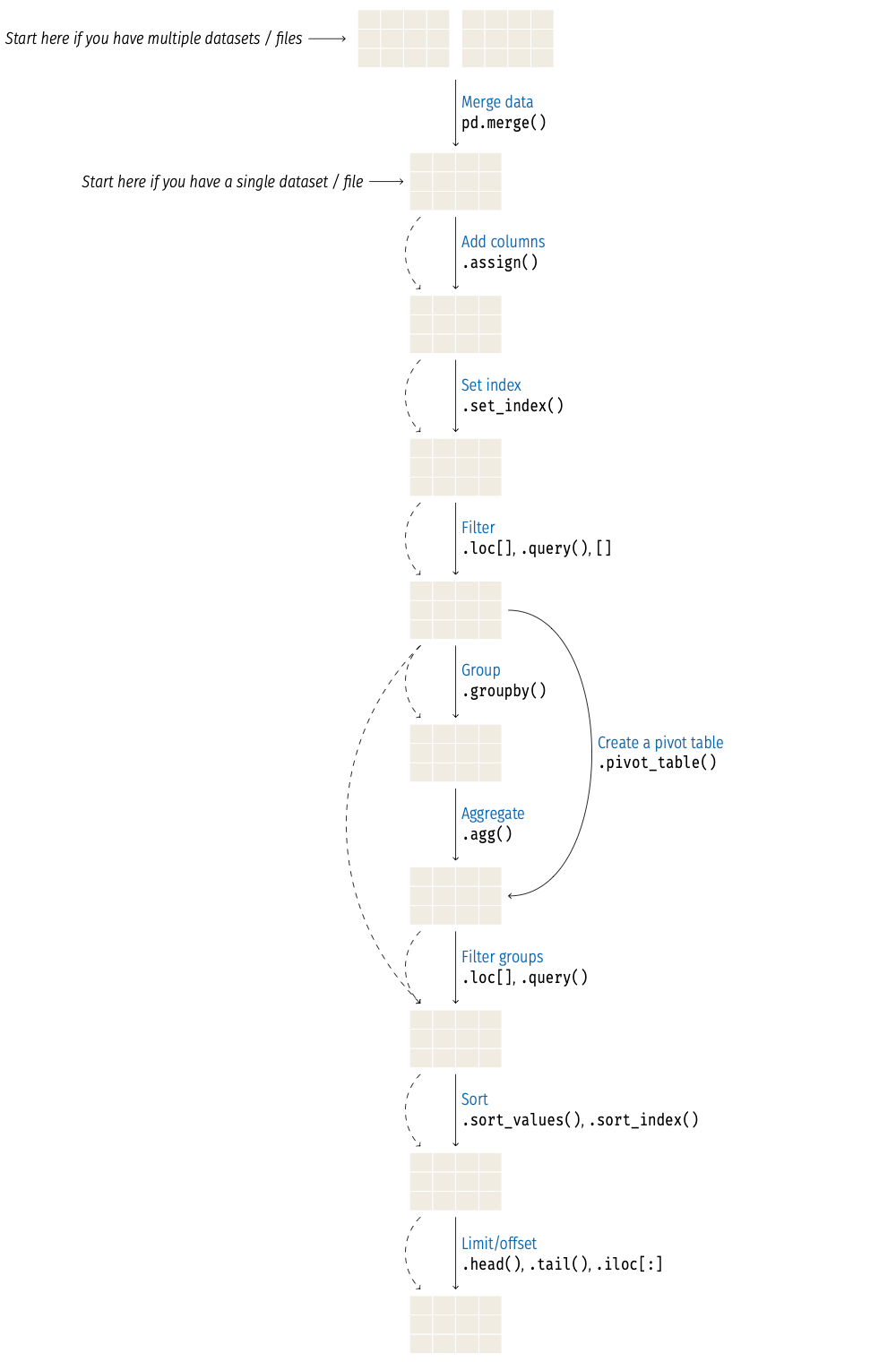
Step-by-step overview
Start (one or multiple datasets) The process often begins with one or more raw data sources such as Excel, CSV, JSON, or database tables. When reading the files, adjust column types if necessary (with
.astype()orpd.to_datetime()).Merge data When information is spread across several tables,
pd.merge()(or similar functions) can be used to combine them into a unified DataFrame.Add or transform columns Derived columns may be added to the DataFrame for convenience in later steps (for example, ratios, flags, or computed metrics). This can be done in-place by assigning to
df["column_name"], or using.assign, which returns a new dataframe.Set index Choose a meaningful column or a combination of columns as an index (or multi-index) using
.set_index. The index may uniquely identify each row or simplify grouping, filtering, and joining operations later.Filter rows and columns Use
.loc[],.query()to filter rows, and[]to select specific columns. Remember that you can use boolean conditions when filtering the data.Group, pivot, and aggregate Next, if needed, group the filtered rows by one or more keys using
.groupby, and calculate summary statistics for each group (with.aggor other aggregate methods). In some cases, you may consider creating a pivot table with.pivot_table.Filter aggregated results After summarization, apply additional filters if needed to focus on specific groups (for example, those with statistics above given thresholds).
Sort results Order the output to highlight patterns, such as top values or alphabetical sorting using
.sort_valuesor.sort_index.Limit and offset Select a subset of rows for reporting or visualization using
.head,.tail, or.iloc[].
The framework is flexible, steps can be combined, reordered, or repeated depending on the analysis. Many operations return new DataFrames, so method chaining is common:
df.merge(...).assign(...).query(...).groupby(...).agg(...)